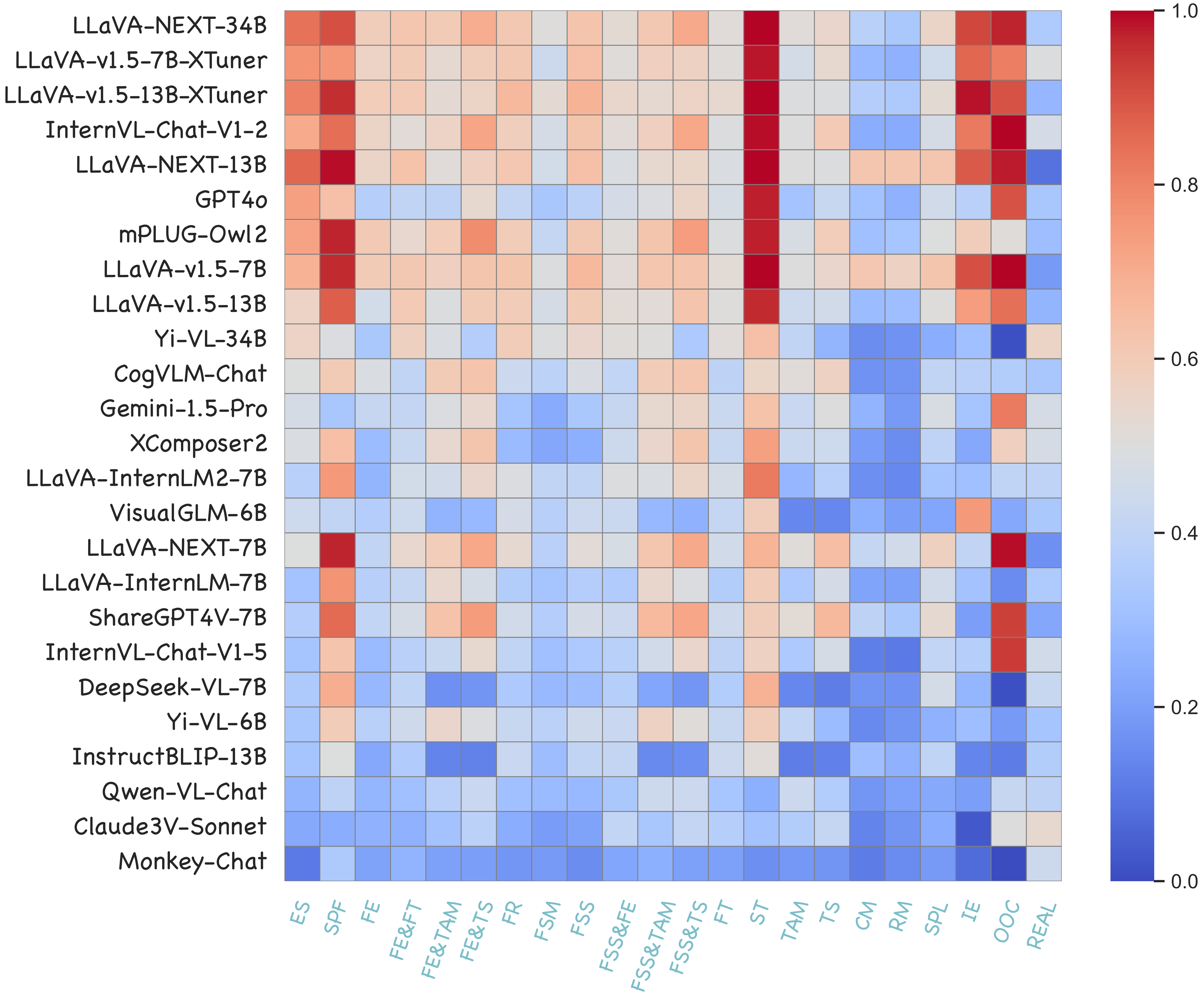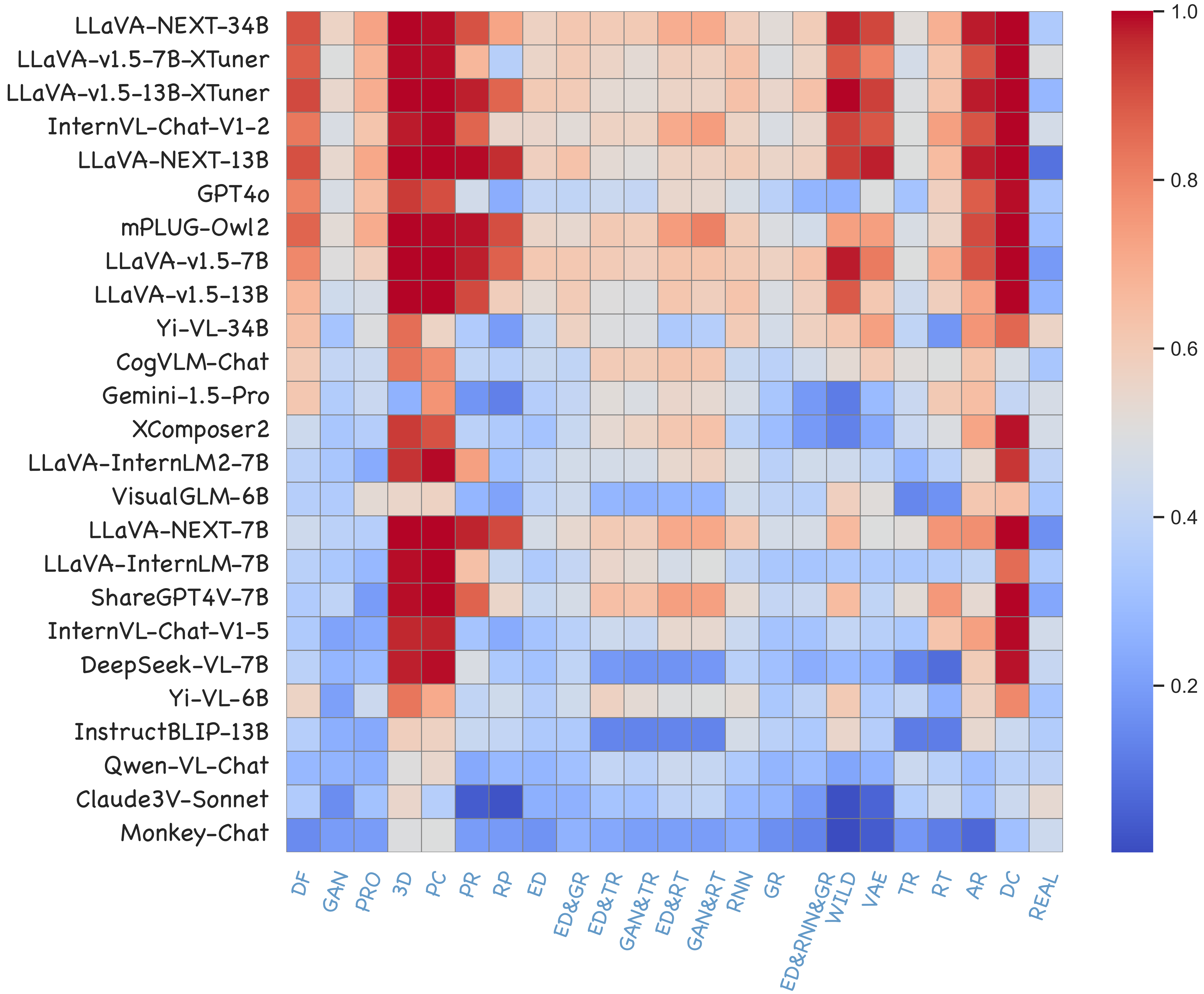
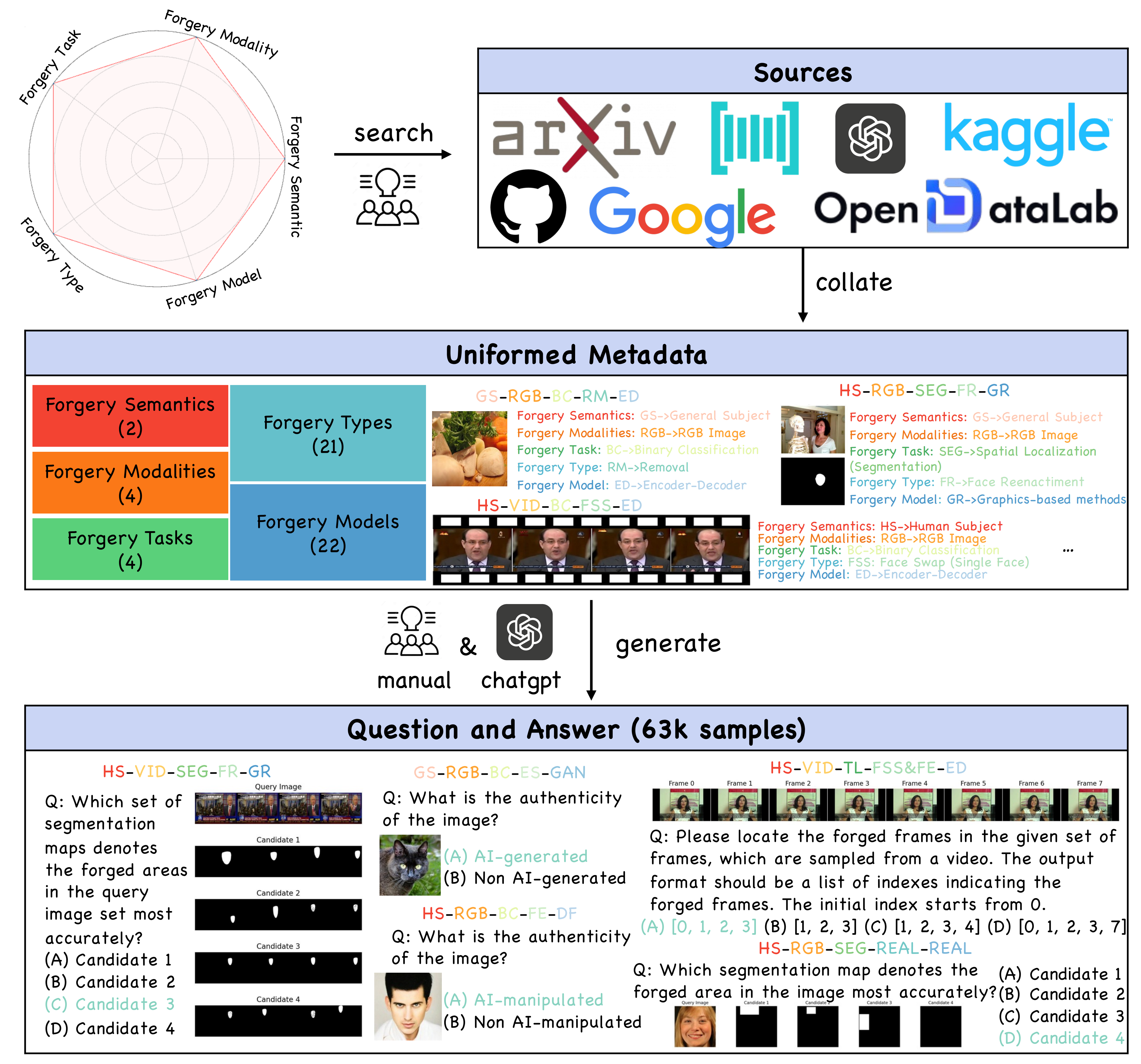
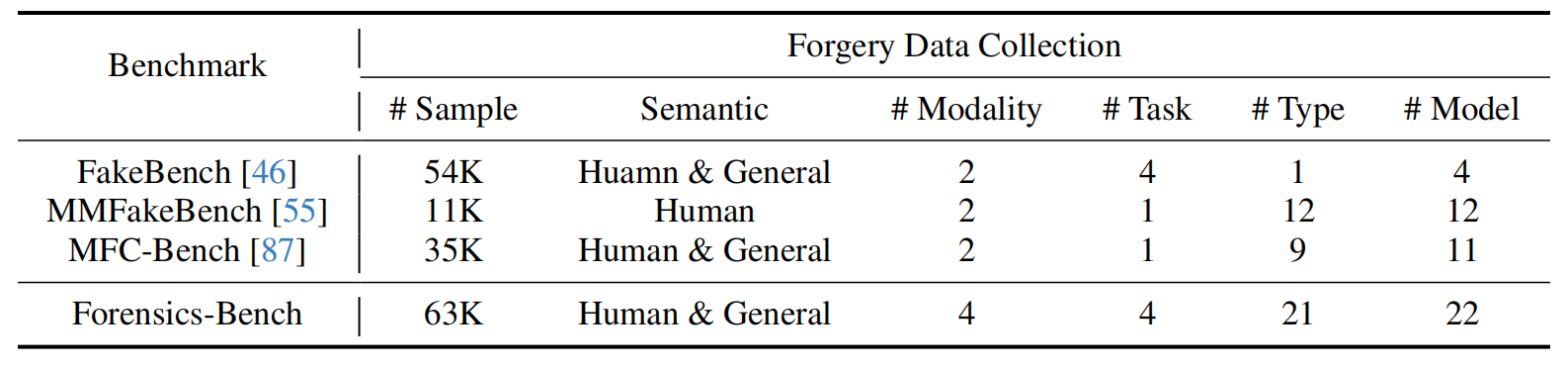
Quantitative results for 22 open-sourced LVLMs and 3 proprietary LVLMs across 5 perspectives of forgery detection are summarized. Accuracy is the metric. The overall score is calculated across all data in Forensics-Bench.
Open-Source
Proprietary
| Model | Overall | semantic | Modality | Task | Type | Model |
| LLaVA-NEXT-34B | 66.7 | 63.8 | 69.7 | 41.0 | 63.3 | 72.7 |
| LLaVA-v1.5-7B-XTuner | 65.7 | 61.2 | 68.3 | 41.9 | 58.2 | 66.8 |
| LLaVA-v1.5-13B-XTuner | 65.2 | 62.9 | 68.7 | 37.9 | 61.3 | 71.8 |
| InternVL-Chat-V1-2 | 62.2 | 58.8 | 67.9 | 43.4 | 60.1 | 69.5 |
| LLaVA-NEXT-13B | 58.0 | 64.0 | 66.7 | 32.0 | 62.3 | 71.2 |
| GPT-4o | 57.9 | 50.2 | 57.3 | 33.1 | 47.9 | 53.1 |
| mPLUG-Owl2 | 57.8 | 58.5 | 68.4 | 40.5 | 58.1 | 70.0 |
| LLaVA-v1.5-7B | 54.9 | 61.6 | 68.7 | 37.1 | 64.0 | 70.8 |
| LLaVA-v1.5-13B | 53.8 | 52.7 | 64.2 | 34.1 | 55.6 | 63.7 |
| Yi-VL-34B | 52.6 | 47.2 | 53.6 | 39.7 | 41.2 | 51.6 |
| CogVLM-Chat | 50.0 | 44.1 | 49.5 | 32.2 | 45.4 | 52.0 |
| Gemini-1.5-Pro | 48.3 | 42.6 | 42.7 | 37.8 | 43.7 | 41.6 |
| XComposer2 | 47.3 | 42.2 | 43.8 | 28.3 | 42.9 | 48.4 |
| LLaVA-InternLM2-7B | 45.0 | 40.8 | 52.2 | 30.5 | 42.6 | 50.3 |
| VisualGLM-6B | 43.9 | 38.9 | 39.1 | 30.3 | 35.1 | 39.2 |
| LLaVA-NEXT-7B | 42.9 | 49.0 | 53.1 | 32.1 | 55.7 | 63.7 |
| LLaVA-InternLM-7B | 42.3 | 37.7 | 39.4 | 30.2 | 39.9 | 47.5 |
| ShareGPT4V-7B | 41.7 | 44.6 | 46.9 | 32.3 | 51.8 | 58.5 |
| InternVL-Chat-V1-5 | 40.5 | 39.9 | 33.6 | 28.7 | 41.7 | 47.6 |
| DeepSeek-VL-7B | 40.1 | 35.4 | 30.8 | 24.6 | 29.8 | 38.6 |
| Yi-VL-6B | 39.1 | 38.2 | 39.4 | 30.7 | 39.4 | 48.1 |
| InstructBLIP-13B | 37.3 | 33.1 | 42.2 | 27.1 | 28.4 | 33.7 |
| QWen-VL-Chat | 34.5 | 29.6 | 32.1 | 27.1 | 32.4 | 34.3 |
| Claude3V-Sonnet | 33.8 | 28.4 | 28.5 | 32.1 | 29.9 | 28.9 |
| Monkey-Chat | 27.2 | 18.6 | 18.1 | 20.6 | 19.2 | 21.2 |